
Dr. Ralf Wagner
Preface
Ralf Wagner deals with the creation of a digital decision support system within the whole project and espacially with the implementation and using of so called artificial neural networks. These take next other components part on the creation of the mentioned system.
Allgemeines
Herr Ralf Wagner beschäftigt sich innerhalb des Gesamtprojektes mit der Entwicklung eines digitalen Entscheidungsunterstützungssystems und dabei speziell mit der Einbindung und Verwendung so genannter künstlicher Neuronaler Netze. Diese liefern neben anderen Komponenten wie den stochastischen Netzen und der Fuzzy-Logik einen Beitrag zur Erstellung des genannten Systems.
Artificial Neural Networks
The reagarded artificial neural networks are located in the research field of neuroempiricism, which is dealing with the searching of rules in empirical data using the modelling of the human information processing.
Artificial neural networks has originally been created to get a better understanding of the human information processing and to take advantages for psychology. But in the course of time there where found many application in different subjects and research fields like physics, computer science and mathematics.
Künstliche Neuronale Netze
Die betrachteten künstlichen Neuronalen Netze entstammen dem Forschungsbereich des Neuroempirismus, welcher sich damit beschäftigt, die Modellierung der menschlichen Informationsverarbeitung zur Auffindung von Gesetzmäßigkeiten in empirischen Daten zu verwenden.
Constitutional Information
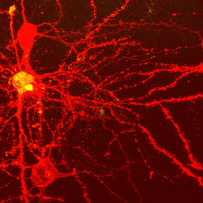
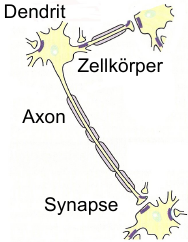
In general, artificial neural networks consist of elementary processing units, so called neurons like it is in the biological antetype. There, the neurons consist of a possibility to get an input (dendrits), of an information processing unit (soma) and of a possibility to transfer the computed output (axon and synapsis). All these components can also be found in an artificial modell on a neuron like it is shown in the following drawing.
Grundlegendes
Künstliche Neuronale Netze wurden ursprünglich dazu entwickelt, um durch Modellbildungsprozesse die Informationsverarbeitung des menschlichen Gehirns besser zu verstehen und daraus einen Nutzen für die Psychologie zu ziehen. Im Laufe der Zeit fanden diese jedoch vielfältige Anwendungen in den unterschiedlichsten Fachrichtungen und Forschungsbereichen, wie beispielsweise der Physik, der Informatik und der Mathematik.
Im Allgemeinen sind künstliche Neuronale Netze aus elementaren Verarbeitungseinheiten, so genannten Neuronen, aufgebaut, so wie es auch im biologischen Vorbild der Fall ist. Diese bestehen dort aus Möglichkeiten der Informationsaufnahme (Dendriten), einer Informationsverarbeitungseinheit (Soma) und Möglichkeiten der Informationsweiterleitung (Axon und Synapse). Entsprechend sind diese Elemente auch bei einem künstlichen Neuronenmodell vorhanden, wie in der folgenden Abbildung dargestellt.
Ralf Wagner deals with the creation of a digital decision support system within the whole project and espacially with the implementation and using of so called artificial neural networks. These take next other components part on the creation of the mentioned system.
Allgemeines
Herr Ralf Wagner beschäftigt sich innerhalb des Gesamtprojektes mit der Entwicklung eines digitalen Entscheidungsunterstützungssystems und dabei speziell mit der Einbindung und Verwendung so genannter künstlicher Neuronaler Netze. Diese liefern neben anderen Komponenten wie den stochastischen Netzen und der Fuzzy-Logik einen Beitrag zur Erstellung des genannten Systems.
Artificial Neural Networks
The reagarded artificial neural networks are located in the research field of neuroempiricism, which is dealing with the searching of rules in empirical data using the modelling of the human information processing.
Artificial neural networks has originally been created to get a better understanding of the human information processing and to take advantages for psychology. But in the course of time there where found many application in different subjects and research fields like physics, computer science and mathematics.
Künstliche Neuronale Netze
Die betrachteten künstlichen Neuronalen Netze entstammen dem Forschungsbereich des Neuroempirismus, welcher sich damit beschäftigt, die Modellierung der menschlichen Informationsverarbeitung zur Auffindung von Gesetzmäßigkeiten in empirischen Daten zu verwenden.
Constitutional Information
In general, artificial neural networks consist of elementary processing units, so called neurons like it is in the biological antetype. There, the neurons consist of a possibility to get an input (dendrits), of an information processing unit (soma) and of a possibility to transfer the computed output (axon and synapsis). All these components can also be found in an artificial modell on a neuron like it is shown in the following drawing.
Grundlegendes
Künstliche Neuronale Netze wurden ursprünglich dazu entwickelt, um durch Modellbildungsprozesse die Informationsverarbeitung des menschlichen Gehirns besser zu verstehen und daraus einen Nutzen für die Psychologie zu ziehen. Im Laufe der Zeit fanden diese jedoch vielfältige Anwendungen in den unterschiedlichsten Fachrichtungen und Forschungsbereichen, wie beispielsweise der Physik, der Informatik und der Mathematik.
Im Allgemeinen sind künstliche Neuronale Netze aus elementaren Verarbeitungseinheiten, so genannten Neuronen, aufgebaut, so wie es auch im biologischen Vorbild der Fall ist. Diese bestehen dort aus Möglichkeiten der Informationsaufnahme (Dendriten), einer Informationsverarbeitungseinheit (Soma) und Möglichkeiten der Informationsweiterleitung (Axon und Synapse). Entsprechend sind diese Elemente auch bei einem künstlichen Neuronenmodell vorhanden, wie in der folgenden Abbildung dargestellt.
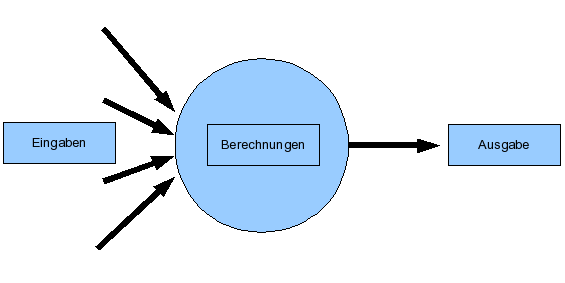
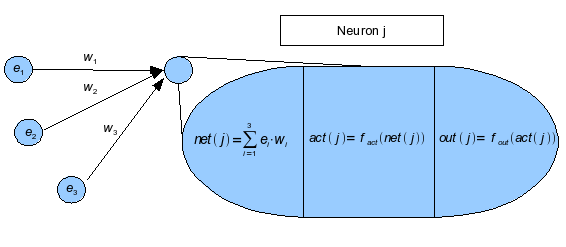
The processing of the input signals is done by using the composition of three functions, the so called propagation- or netinput function, the activation function and the output function. This is shawn in the next drawing, where the neuron "j" and the three neurons "e1", "e2" and "e3" are connectted, which transfer their outputs to this neuron. Each connection is weightened by the according weights "w1", "w2" and "w3", which models the different synaptical connections in the biological neural network. Th function net(j) describes the propagation function, act(j) the activation function and out(j) the output function of the neuron "j".
Die Verarbeitung der Eingabesignale erfolgt durch die Komposition von drei Funktionen, der so genannten Propagierungs- oder Netzeingabefunktion, der Aktivierungsfunktion und der Ausgabefunktion. Dies ist in der nächsten Abbildung dargestellt, wobei das Neuron "j" mit den drei Neuronen "e1", "e2" und "e3" verbunden ist, welche ihre Ausgaben an dieses Neuron weiterleiten. Die jeweiligen Verbindungen sind außerdem durch die entsprechenden Gewichte "w1", "w2" und "w3" gewichtet, was die unterschiedliche synaptische Verbindung im biologischen Neuronalen Netz modelliert. Die Funktion net(j) beschreibt die Propagierungsfunktion, act(j) die Aktivierungsfunktion und out(j) die Ausgabefunktion des Neurons "j".
Die Verarbeitung der Eingabesignale erfolgt durch die Komposition von drei Funktionen, der so genannten Propagierungs- oder Netzeingabefunktion, der Aktivierungsfunktion und der Ausgabefunktion. Dies ist in der nächsten Abbildung dargestellt, wobei das Neuron "j" mit den drei Neuronen "e1", "e2" und "e3" verbunden ist, welche ihre Ausgaben an dieses Neuron weiterleiten. Die jeweiligen Verbindungen sind außerdem durch die entsprechenden Gewichte "w1", "w2" und "w3" gewichtet, was die unterschiedliche synaptische Verbindung im biologischen Neuronalen Netz modelliert. Die Funktion net(j) beschreibt die Propagierungsfunktion, act(j) die Aktivierungsfunktion und out(j) die Ausgabefunktion des Neurons "j".
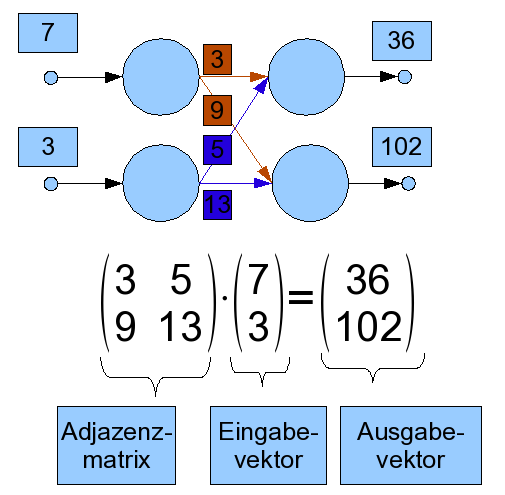
It is possible to create many different topologies of such networks by using various combinations of single neurons. Such an artificial neural network can mathematicaly be described as a directed graph, whose knots represents the neurons and whose vertexes represents the connections. It is possible to describe such a graph by using a so called adjacency matrix, which simplifies the calculation of outputs of the network. Therefore, the weights of the connections, which lead to each neuron, are noticed as a matrix line by line. Each row represents a neuron. All inputs to the network are put together to a so called input vector, all outputs to an output vector. The calculation of an output is simply done by a multiplikation of the adjacency matrix and the input vector, like it is shown in the following illustration.
Durch unterschiedliche Verknüpfungen solcher einzelner Nerone können die verschiedensten Netzwerktopologien entstehen. Dabei kann ein solches künstliches Neuronales Netz mathematisch als gerichteter Graph angesehen werden, dessen Knoten die einzelnen Neurone und dessen Kanten die jeweiligen Verbindungen darstellen. Einen solchen Graphen kann man durch eine entsprechende so genannte Adjazenzmatrix beschreiben, was Berechnungen von Ausgaben des Netzwerkes erleichtert. Dabei werden die Gewichte der entsprechenden Verbindungen, welche zu einem Neuron vorhanden sind, zeilenweise als Matrix notiert. Jede Zeile entspricht dann einem Neuron. Alle Eingaben an das Neuronale Netz werden zu einem Eingabevektor, alle Ausgaben zu einem Ausgabevektor zusammengefasst. Die Berechnung der jeweiligen Ausgabe erfolgt durch Multiplikation der entsprechenden Adjazenzmatrix mit dem Eingabevektor, wie in der nachfolgenden Abbildung verdeutlicht.
Durch unterschiedliche Verknüpfungen solcher einzelner Nerone können die verschiedensten Netzwerktopologien entstehen. Dabei kann ein solches künstliches Neuronales Netz mathematisch als gerichteter Graph angesehen werden, dessen Knoten die einzelnen Neurone und dessen Kanten die jeweiligen Verbindungen darstellen. Einen solchen Graphen kann man durch eine entsprechende so genannte Adjazenzmatrix beschreiben, was Berechnungen von Ausgaben des Netzwerkes erleichtert. Dabei werden die Gewichte der entsprechenden Verbindungen, welche zu einem Neuron vorhanden sind, zeilenweise als Matrix notiert. Jede Zeile entspricht dann einem Neuron. Alle Eingaben an das Neuronale Netz werden zu einem Eingabevektor, alle Ausgaben zu einem Ausgabevektor zusammengefasst. Die Berechnung der jeweiligen Ausgabe erfolgt durch Multiplikation der entsprechenden Adjazenzmatrix mit dem Eingabevektor, wie in der nachfolgenden Abbildung verdeutlicht.
In general, there are two main fields where artificial neural networks are applied. On the one, there is the approximation of functional relationships and on the other, there ist classification and clusteranalysis.
Im Allgemeinen kann man zwei große Bereiche nennen, in welchen künstliche Neuronale Netze eine Anwendung finden. Dies sind zum Einen die Approximation funktionaler Zusammenhänge und zum Anderen Klassifikationsaufgaben und Clusteranalyseanforderungen.
Approximation of functional relationships
This problem can be solved by using so called Backpropagation or Feed-Forward networks. These are artificial neural networks, which are arranged in layers and each neuron of one layer is connected with each neuron of the following layer. To solve the problem of approximation, there have to be some training data containing input vectors and suitable output vectors. By using a certain training algorithm there should be found an approximately mapping between the input and the output vectors while changing the weights of the connections. Is then a input vector given, which was not trained, a suitable outputvector can be calculated using the adjacency matrix.
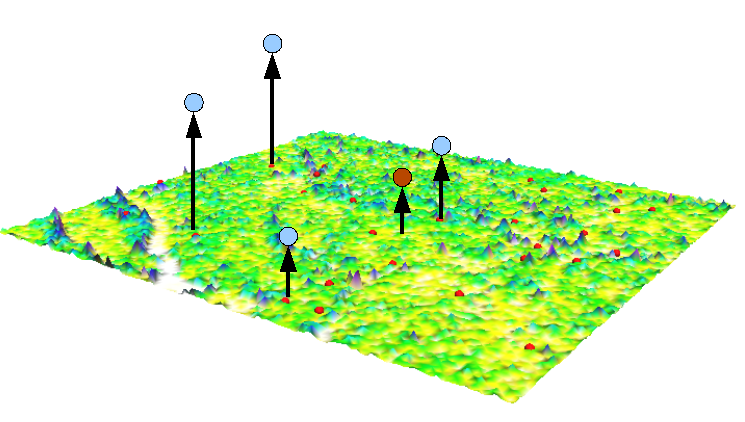
Advantages of this procedure can be seen in the realisation of local characteristics and this is the reason, why this method can be used for calculation and approximation of riskmaps by using discrete riskdata as an alternative to traditionally method for approximation and interpolation. Furthermore, it is not necessary to do the whole calculation again when there is some new data, because this method works adaptive and integrates this data in the further training. Such an Approximation is shown in the following illustration where the blue dots represents training data and the red dot represents a risk prediction of an element which was not trained.
Approximation funktionaler Zusammenhänge
Diese Aufgabe kann beispielsweise durch so genannte Backpropagation- oder Feed-Forward-Netze bearbeitet werde. Dabei handelt es sich um künstliche Neuronale Netze, welche in Schichten angeordnet sind und dessen Schichten vollständig miteinander verbunden sind, d.h. jedes Neuron einer Schicht ist mit jedem Neuron der nächsten Schicht verbunden. Zur Bearbeitung der Approximationsaufgabe müssen Trainingsdaten, bestehend aus Eingabevektoren und entsprechenden Ausgabevektore,n vorhanden sein. Durch einen Trainingsalgorithmus wird nun versucht, die gegebenen Eingabevektoren durch Veränderung der Verbindungsgewichte "möglichst gut" auf die entsprechenden Ausgabevektoren abzubilden. Durch weitere Daten wird diese Abbildung immer besser. Wird nun ein nicht trainierter Eingabevektor eingegeben, dann wird durch die entsprechende Adjazenz- oder Gewichtsmatrix ein Ausgabevektor berechnet.
Vorteile dieses Verfahrens sind in der Erkennung lokaler Besonderheiten zu sehen, wodurch es sich für die Approximation von Risikooberflächen ausgehend von diskreten Risikodaten als Alternative zu herkömmlichen Interpolations- und Approximationsverfahren eignet. Außerdem muss nicht bei jedem neuen Risikodatum die ganze Berechnung von vorne erfolgen, sondern das Verfahren arbeitet adaptiv und integriert diese Informationen während des weiteren Trainings. Eine solche Approximation ist in der folgenden Abbildung dargestellt, wobei die blauen Punkte Trainingselemente und der rote Punkt eine Risikoaussage nicht trainiertes Element darstellen.
Im Allgemeinen kann man zwei große Bereiche nennen, in welchen künstliche Neuronale Netze eine Anwendung finden. Dies sind zum Einen die Approximation funktionaler Zusammenhänge und zum Anderen Klassifikationsaufgaben und Clusteranalyseanforderungen.
Approximation of functional relationships
This problem can be solved by using so called Backpropagation or Feed-Forward networks. These are artificial neural networks, which are arranged in layers and each neuron of one layer is connected with each neuron of the following layer. To solve the problem of approximation, there have to be some training data containing input vectors and suitable output vectors. By using a certain training algorithm there should be found an approximately mapping between the input and the output vectors while changing the weights of the connections. Is then a input vector given, which was not trained, a suitable outputvector can be calculated using the adjacency matrix.
Advantages of this procedure can be seen in the realisation of local characteristics and this is the reason, why this method can be used for calculation and approximation of riskmaps by using discrete riskdata as an alternative to traditionally method for approximation and interpolation. Furthermore, it is not necessary to do the whole calculation again when there is some new data, because this method works adaptive and integrates this data in the further training. Such an Approximation is shown in the following illustration where the blue dots represents training data and the red dot represents a risk prediction of an element which was not trained.
Approximation funktionaler Zusammenhänge
Diese Aufgabe kann beispielsweise durch so genannte Backpropagation- oder Feed-Forward-Netze bearbeitet werde. Dabei handelt es sich um künstliche Neuronale Netze, welche in Schichten angeordnet sind und dessen Schichten vollständig miteinander verbunden sind, d.h. jedes Neuron einer Schicht ist mit jedem Neuron der nächsten Schicht verbunden. Zur Bearbeitung der Approximationsaufgabe müssen Trainingsdaten, bestehend aus Eingabevektoren und entsprechenden Ausgabevektore,n vorhanden sein. Durch einen Trainingsalgorithmus wird nun versucht, die gegebenen Eingabevektoren durch Veränderung der Verbindungsgewichte "möglichst gut" auf die entsprechenden Ausgabevektoren abzubilden. Durch weitere Daten wird diese Abbildung immer besser. Wird nun ein nicht trainierter Eingabevektor eingegeben, dann wird durch die entsprechende Adjazenz- oder Gewichtsmatrix ein Ausgabevektor berechnet.
Vorteile dieses Verfahrens sind in der Erkennung lokaler Besonderheiten zu sehen, wodurch es sich für die Approximation von Risikooberflächen ausgehend von diskreten Risikodaten als Alternative zu herkömmlichen Interpolations- und Approximationsverfahren eignet. Außerdem muss nicht bei jedem neuen Risikodatum die ganze Berechnung von vorne erfolgen, sondern das Verfahren arbeitet adaptiv und integriert diese Informationen während des weiteren Trainings. Eine solche Approximation ist in der folgenden Abbildung dargestellt, wobei die blauen Punkte Trainingselemente und der rote Punkt eine Risikoaussage nicht trainiertes Element darstellen.
Classification and Clusteranalysis When
classification problems are handled, elements are put in certain
classes depending on their characteristics. It is exemplarily possible,
to classify geographical locations while having a look at illness cases,
annual rainfall and the intensity of the sunlight to different risk
classes. This classification works adaptive, that means if there is a
changing of some parameter, the whole classification changes in a
suitable way and the more data is available the merrier is the
classification.
A kind of artificial neural networks, which can handle such problems, are so called selforganizing maps. One of these are the Kohonen networks. By using the learning algorithm of this network, the weights of the connections are trained in a way that one neuron is responsible for a certain area of the input field, which leads to the creation of the mentioned classes.
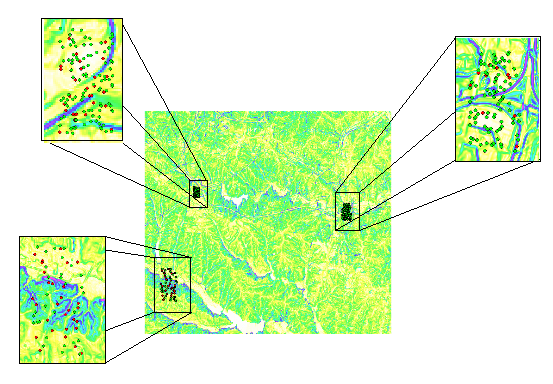
This kind of artificial neural networks can also be used for data reduction. A lot of geographically and epidemiologically tasks there is a huge amount of data, which can be reduced and clustered by using this method in a suitable way. This is shown in the following illustration, where on the left, there is the original data and on the right there are shown the cluster in red color, which were created while the processing of the artificial neural network.
Klassifikationsaufgaben und Clusteranalyseanforderungen
Bei Klassifikationsaufgaben werden Elemente je nach Eigenschaften unterschiedlichen Klassen zugeordnet. So ist es beispielsweise möglich, geographischen Orten unter Berücksichtigung verschiedener Parameter wie bereits aufgetretene Krankheitsfälle, jährliche Niederschlagsmenge und Intensität der Sonneneinstrahlung unterschiedlichen Risikoklassen zuzuordnen. Diese Zuordnung erfolgt adaptiv, d.h. wenn sich Parameter ändern, dann ändert sich auch atomatisch die entsprechende Klassenzuordnung und je mehr Informationen vorhanden sind, desto besser ist die Klassifikation.
Eine Art von künstlichen Neuronalen Netzen, welche solche Aufgaben bearbeiten kann, sind so genannte Selbstorganisierende Karten. Dazu gehören beispielsweise die so genannten Kohonen-Netze. Durch den dort verwendeten Lernalgorithmus werden die entsprechenden Verbindungsgewichte so trainiert, dass ein Neuron jeweils für einen Bereich des Eingaberaumes zuständig ist, was zur Bildung der erwähnten Klassen führt.
Diese Art von künstlichen Neuronalen Netzen kann auch gut zur Datenreduktion verwendet werden. Bei vielen geographischen und epidemiologischen Aufgabenstellungen treten eine Fülle von Daten auf, welche so sinnvoll reduziert und geclustert werden können. Dies ist auf der nachfolgenden Abbildung zu sehen, wobei links die ursprünglichen Daten und rechts in rot die durch die Verarbeitung des künstlichen Neuronalen Netzes erhaltenen Cluster zu sehen sind.
A kind of artificial neural networks, which can handle such problems, are so called selforganizing maps. One of these are the Kohonen networks. By using the learning algorithm of this network, the weights of the connections are trained in a way that one neuron is responsible for a certain area of the input field, which leads to the creation of the mentioned classes.
This kind of artificial neural networks can also be used for data reduction. A lot of geographically and epidemiologically tasks there is a huge amount of data, which can be reduced and clustered by using this method in a suitable way. This is shown in the following illustration, where on the left, there is the original data and on the right there are shown the cluster in red color, which were created while the processing of the artificial neural network.
Klassifikationsaufgaben und Clusteranalyseanforderungen
Bei Klassifikationsaufgaben werden Elemente je nach Eigenschaften unterschiedlichen Klassen zugeordnet. So ist es beispielsweise möglich, geographischen Orten unter Berücksichtigung verschiedener Parameter wie bereits aufgetretene Krankheitsfälle, jährliche Niederschlagsmenge und Intensität der Sonneneinstrahlung unterschiedlichen Risikoklassen zuzuordnen. Diese Zuordnung erfolgt adaptiv, d.h. wenn sich Parameter ändern, dann ändert sich auch atomatisch die entsprechende Klassenzuordnung und je mehr Informationen vorhanden sind, desto besser ist die Klassifikation.
Eine Art von künstlichen Neuronalen Netzen, welche solche Aufgaben bearbeiten kann, sind so genannte Selbstorganisierende Karten. Dazu gehören beispielsweise die so genannten Kohonen-Netze. Durch den dort verwendeten Lernalgorithmus werden die entsprechenden Verbindungsgewichte so trainiert, dass ein Neuron jeweils für einen Bereich des Eingaberaumes zuständig ist, was zur Bildung der erwähnten Klassen führt.
Diese Art von künstlichen Neuronalen Netzen kann auch gut zur Datenreduktion verwendet werden. Bei vielen geographischen und epidemiologischen Aufgabenstellungen treten eine Fülle von Daten auf, welche so sinnvoll reduziert und geclustert werden können. Dies ist auf der nachfolgenden Abbildung zu sehen, wobei links die ursprünglichen Daten und rechts in rot die durch die Verarbeitung des künstlichen Neuronalen Netzes erhaltenen Cluster zu sehen sind.

Calculation of distribution densities Should
there be predictions to the regardeded area by using measured values
exemplarily of meteorlogical or epidemiological data, it is very
important to take a look at the distribution and the density of the
data. The cases of malaria which were registred in a certain area should
be regarded and they are shown at the following illustration.
Berechnung von Verteilungsdichten
Werden auf Grund gemessener Werte wie beispielsweise meteorologischer oder epidemiologischer Daten Aussagen über das betrachtete Gebiet gemacht, dann ist es sehr wichtig, die entsprechende Verteilung dieser Daten zu betrachten und deren Dichte zu beachten. Es sollen die in einem bestimmten geographischen Bereich aufgetretenen Malariafälle betrachtet werden, welche wie auf der folgenden Abbildung dargestellt verteilt sind.
Berechnung von Verteilungsdichten
Werden auf Grund gemessener Werte wie beispielsweise meteorologischer oder epidemiologischer Daten Aussagen über das betrachtete Gebiet gemacht, dann ist es sehr wichtig, die entsprechende Verteilung dieser Daten zu betrachten und deren Dichte zu beachten. Es sollen die in einem bestimmten geographischen Bereich aufgetretenen Malariafälle betrachtet werden, welche wie auf der folgenden Abbildung dargestellt verteilt sind.
At each considered area, there has been analized a different amount of persons. The red dots represents the positive cases, the green dots the negative ones. If we have a look at the two areas on the left, there are 30 positive cases each, but the number of the persons, which have been analysed at all is very different. In the area at the bottom, there have been analyzed 60 persons (30 positive and 30 negative ones), in the area on the top 130 persons (30 positive and 100 negative ones). Therefor, it wouldn't be right, to make the statement, that the possibility to get malaria is higher in the area on the bottom. Furthermore, the considered geographical region has not the same area.
To be able to make statements about the validity and the amount of information of a measurement, Ralf Wagner has a look at the calculation of suitable information densities. These can then be used in the considered digital decision support system to estimate the validity of prognosises and decision advices.
In the following illustration there is shown the calculation of an information density function by using a reduction of the data and an interpolation.
Es wurden unterschiedlich viele Personen untersucht. Die roten Punkte sind positiv getestet, die grünen negativ. Vergleicht man die beiden Bereiche links, dann sind jeweils 30 positiv getestete Personen vorhanden, aber die Anzahl der in dem jeweiligen Bereich überhaupt betrachteten Personen ist sehr unterschiedlich. Im unteren Bereich sind es nur 60 Personen (30 positiv und 30 negativ), im oberen Bereich hingegen 130 (30 positiv und 100 negativ). Es wäre also nicht unbedingt richtig, auszusagen, dass die Wahrscheinlichkeit, an Malaria zu erkranken, im unteren Bereich höher ist, als im oberen. Außerdem sind die betrachteten geographischen Bereiche nicht von der selben Fläche.
Um Beurteilungen über die Aussagekräftigkeit und den vorhandenen Informationsgehalt einer Messung geben zu können, beschäftigt sich Herr Wagner mit der Berechnung entsprechender Informationsdichten. Diese können dann im oben erwähnten digitalen Entscheidungsunterstützungssystem dazu verwendet werden, um die Aussagefähigkeit von Prognosen und Entscheidungsvorschlägen zu beurteilen.
Die Erstellung einer Informationsdichte mit Hilfe einer Reduktion der vorhandenen Daten und Interpolation ist in der folgenden Abbildung dargestellt.
To be able to make statements about the validity and the amount of information of a measurement, Ralf Wagner has a look at the calculation of suitable information densities. These can then be used in the considered digital decision support system to estimate the validity of prognosises and decision advices.
In the following illustration there is shown the calculation of an information density function by using a reduction of the data and an interpolation.
Es wurden unterschiedlich viele Personen untersucht. Die roten Punkte sind positiv getestet, die grünen negativ. Vergleicht man die beiden Bereiche links, dann sind jeweils 30 positiv getestete Personen vorhanden, aber die Anzahl der in dem jeweiligen Bereich überhaupt betrachteten Personen ist sehr unterschiedlich. Im unteren Bereich sind es nur 60 Personen (30 positiv und 30 negativ), im oberen Bereich hingegen 130 (30 positiv und 100 negativ). Es wäre also nicht unbedingt richtig, auszusagen, dass die Wahrscheinlichkeit, an Malaria zu erkranken, im unteren Bereich höher ist, als im oberen. Außerdem sind die betrachteten geographischen Bereiche nicht von der selben Fläche.
Um Beurteilungen über die Aussagekräftigkeit und den vorhandenen Informationsgehalt einer Messung geben zu können, beschäftigt sich Herr Wagner mit der Berechnung entsprechender Informationsdichten. Diese können dann im oben erwähnten digitalen Entscheidungsunterstützungssystem dazu verwendet werden, um die Aussagefähigkeit von Prognosen und Entscheidungsvorschlägen zu beurteilen.
Die Erstellung einer Informationsdichte mit Hilfe einer Reduktion der vorhandenen Daten und Interpolation ist in der folgenden Abbildung dargestellt.
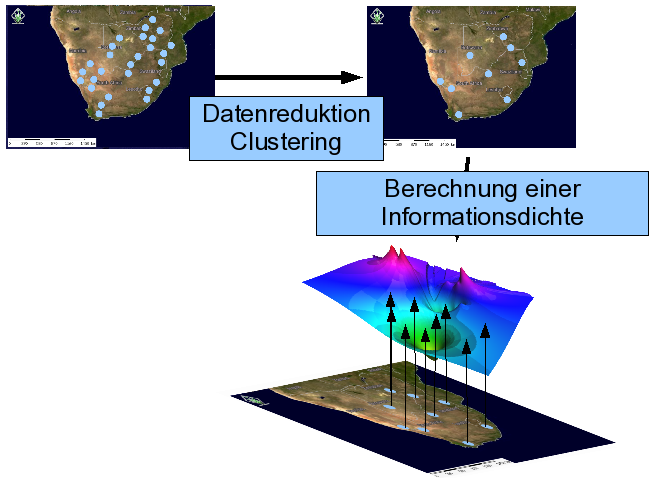
There, the green color represents areas of a lower amount of information and the red color represents the ones of a higher amount of information. In the appropriate areas, predictions can be more or less good.
In dieser Abbildung erkennt man an der grünen Farbe der Informationsdichtefunktion Bereiche mit geringem Informationsgehalt und an der roten Farbe Bereiche mit höherem Informationsgehalt. In den entsprechenden Bereichen sind mögliche Aussagen also mehr oder weniger gut.
References:
Cartographical material: GRASS Development Team under GNU General Public License
(http://mapserver.gdf-hannover.de/grassusers/map.phtml?winwidth=890&
winheight=630&language=1&mapwidth=600&mapheight=400)
Quellennachweis:
Kartenmaterial: GRASS Development Team unter der GNU General Public License
(http://mapserver.gdf-hannover.de/grassusers/map.phtml?winwidth=890&
winheight=630&language=1&mapwidth=600&mapheight=400) .
In dieser Abbildung erkennt man an der grünen Farbe der Informationsdichtefunktion Bereiche mit geringem Informationsgehalt und an der roten Farbe Bereiche mit höherem Informationsgehalt. In den entsprechenden Bereichen sind mögliche Aussagen also mehr oder weniger gut.
References:
Cartographical material: GRASS Development Team under GNU General Public License
(http://mapserver.gdf-hannover.de/grassusers/map.phtml?winwidth=890&
winheight=630&language=1&mapwidth=600&mapheight=400)
Quellennachweis:
Kartenmaterial: GRASS Development Team unter der GNU General Public License
(http://mapserver.gdf-hannover.de/grassusers/map.phtml?winwidth=890&
winheight=630&language=1&mapwidth=600&mapheight=400) .
